NeurIPS 2025 Official Sharing: What Changed, What Worked, and What’s Next
-
NeurIPS 2025 continued to run the world’s largest peer-review operation while piloting process changes across three poster-session tracks: the Main Program, Datasets & Benchmarks (DB), and the new Position Paper track. The big picture: scale keeps rising, decision calibration is doing more heavy lifting, and this year’s responsible reviewing policies shaped outcomes in visible ways. Below, I synthesize the three official reflections and add cross-track insights, concrete takeaways for authors, and a closing note on community conduct.

Key numbers at a glance
Track Submissions considered Accepted Acceptance rate Notes Main Program 21,575 valid 5,290 24.52% Space constraints ultimately negligible; acceptance aligned with reviewer impressions after calibration. Datasets & Benchmarks 1,995 (not disclosed) Expected to align with main track Growth stabilizing; deeper alignment with Main; new scoring + ranking form; 2024 acceptance was 25.3% for reference. Position Papers (pilot) ~496 viable (from ~700 initial) 40 ~8% Small, deliberately selective cohort to amplify discussion; adjudication channel piloted.
Main Program: Calibration as the stabilizer in a noisy, expanding system
Original blog: https://blog.neurips.cc/2025/09/30/reflections-on-the-2025-review-process-from-the-program-committee-chairs/
What changed / mattered
- Scale is the root challenge. Submissions grew to 21,575 (from 9,467 in 2020). Recruiting widened, leading to more first-time ACs and varying topical depth as new areas (e.g., LLMs) surge.
- Calibration became decisive. Where reviewers disagreed (or diverged from the AC), AC–SAC consensus frequently determined outcomes.
- Some papers with modest scores were accepted after AC advocacy and SAC agreement.
- Some high-scoring papers were rejected when ACs surfaced substantial issues post-rebuttal and SACs concurred.
- Responsible reviewing policies influenced decisions. PCs could withhold reviews from authors who missed reviewing obligations; in cases of grossly negligent reviewing, co-authored papers were desk-rejected. (The post notes 11 such confirmed cases.)
- Venue capacity wasn’t the limiter. Final accepts came in below the venue’s capacity—decisions were governed by scientific merit after calibration, not by space.
- Human bandwidth is finite. Calls to extend rebuttals (e.g., when ACs raise new issues) were declined because they would derail conference timelines. The post frames decisions as constrained optimization under bandwidth limits.
- Emerging behavioral signal: Some reviewers reportedly inflated scores to end back-and-forth with authors yet left critical private comments to the AC. Chairs invite feedback and in-person discussion at the Town Hall.
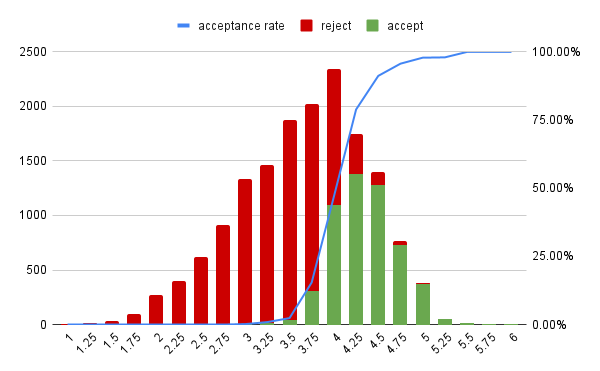
Reviewer score distribution with accept vs. reject coloring.Takeaways for authors (Main)
- Write for two audiences: (1) reviewers and (2) the AC/SAC who will calibrate edge cases; make weaknesses/assumptions explicit.
- Expect tighter enforcement of reviewer obligations and integrity safeguards (less reliance on bidding; more on algorithmic matching).
- Don’t assume space constraints will save borderline cases; scientific rigor is the lever.
Datasets & Benchmarks: Maturing standards, tighter scoring bands, and relative ranking
Original blog: https://blog.neurips.cc/2025/09/30/reflecting-on-the-2025-review-process-from-the-datasets-and-benchmarks-chairs/
What changed / mattered
- Stabilizing growth. DB received 1,995 submissions (1,820 last year; 987 in 2023) — signs of maturation rather than exponential growth.
- Deeper alignment with Main. Common recruiting, shared procedures, and responsible reviewing were adopted, while keeping DB-specific considerations.
- Updated scoring + qualitative ranking.
- New scoring system + the nature of DB papers (rarely “technically incorrect”; subjective impact) produced higher averages with a tighter spread.
- To differentiate near-tied papers, SACs produced relative rankings within their stacks, documented via a ranking form.
- For any paper below the track-wide mean (4.25), SACs had to justify the ranking qualitatively, adding richer signals beyond raw scores.
- Raising the bar for datasets. The track clarified best practices and requirements (hosting, persistence, documentation, reproducibility) so datasets remain accessible and evaluable over time, and to handle “blended” works (e.g., benchmarks straddling tracks).

Takeaways for authors (DB)
- Treat the paper + asset as a product: hosting longevity, licensing clarity, documentation depth, reproducibility.
- In tight scoring bands, AC/SAC qualitative differentiation matters, clearly argue use-case, coverage, stewardship plan, and why this dataset/benchmark unlocks new science.
Position Papers (pilot): A small, amplified cohort with new process levers
Original blog: https://blog.neurips.cc/2025/10/02/reflecting-on-the-inaugural-neurips-position-paper-track-a-pilot-year-journey/
What changed / mattered
- Deliberately selective acceptance (~8%): 40 papers accepted from 496 viable to provide focused attention and tailored presentation/communication support.
- Adjudication channel (pilot). Built to address reviewer behavior concerns (not to relabel scores). All author inputs (surveys + adjudication) were visible to ACs/PCs for metareviews/decisions. Some investigations into reviewer conduct continue.
- Process trade-offs.
- No traditional rebuttal; instead, an author survey and adjudication window.
- Timeline slips occurred due to emergency reviewer needs and uncertainty about expectations in a novel track; organizers emailed authors to prepare resubmissions elsewhere before decisions.
- Lessons called out by chairs.
- Provide clearer exemplars of “what belongs” in a position paper and review expectations.
- Over-recruit reviewers (and over-assign) to assure ≥3 reviews on time.
- Target broader, meaningful discussions; consider higher acceptance in future iterations.
- Improve communications (OpenReview posts and blogs didn’t reach everyone).
Takeaways for authors (Position)
- Lead with a crisp thesis for a broad audience; emphasize the why now and how the position shapes the field’s agenda beyond technical implementation.
- Assume novel logistics and timeline risk in pilot years; submit with contingency plans for other venues.
- Use the author survey to show how the work would evolve based on feedback.
Cross-track themes: What the three pfficial posts collectively signal
- Calibration is the backbone. With wider recruiting and topic breadth, AC/SAC consensus increasingly arbitrates boundary cases across tracks. Prepare manuscripts to survive beyond numerical scores.
- Integrity measures are here to stay. Responsible reviewing (enforcing obligations, penalizing negligence, less trust in bidding, scrutiny of collusion/fake accounts) shifts the operational burden but protects fairness.
- Process realism over idealism. Chairs emphasize finite bandwidth and fixed calendars; not every fair-in-isolation policy (e.g., second rebuttal window) is feasible at NeurIPS scale.
- Maturing specialization. DB’s requirements and Position’s format show track identities sharpening, yet procedural convergence with the Main Track continues where it helps fairness and quality.
- Communication gaps remain. Important updates sometimes miss authors; Town Halls and clearer exemplars are urged.
Practical guidance for 2026 submitters
For all tracks
- Write for calibration: front-load core claims, decision-critical evidence, and limitations, so AC/SAC can defend your paper.
- Anticipate integrity checks: declare assets, authorship, and reviewing roles transparently; avoid conflicts; follow reviewer obligations.
- Reduce friction: make replication and artifact access effortless (code, data cards, licenses, system diagrams).
For DB
- Provide a stewardship plan (maintenance horizon, versioning, governance).
- Show distinctiveness vs. existing assets (coverage gaps, long-tail value) and robust evaluation protocols.
For Position
- Anchor on a field-shaping argument, not an implementation report.
- Use visuals sparingly but effectively to frame the debate (e.g., landscapes, risk/benefit matrices).
Open questions NeurIPS might explore
- Score
 decision transparency: Can calibrated decisions be summarized post hoc (privacy-preserving) to explain reversals where ratings and outcomes diverge?
decision transparency: Can calibrated decisions be summarized post hoc (privacy-preserving) to explain reversals where ratings and outcomes diverge? - Reviewer behavioral signals: How to detect and mitigate score inflation to end discussion?
- Communication reach: What channels (beyond blog + OpenReview) reliably reach all authors in time—dashboards, push notifications, regional mirrors?
- Pilot resourcing: If pilots (like Position) aim for higher acceptance and broad discourse, what’s the sustainable reviewer model?
On threats and respect: a non-negotiable norm
A recent public note from NeurIPS and statements from community groups (e.g., cspaper.org) condemn threatening or disrespectful messages directed at volunteer organizers. This is unequivocal:
- Volunteers deserve safety and respect. Disagreement about decisions is legitimate; harassment is not and may be pursued as code-of-conduct violations.
- Constructive feedback channels exist: Town Halls, surveys, and direct communications to track chairs. Use them; document concerns; engage professionally.
- We all share the incentive: rigorous, fair peer review at scale. Civility is not politeness theater; it’s the infrastructure that keeps expert labor willing and able to show up next year.
Bottom line
NeurIPS 2025 made deliberate choices to preserve quality under historic scale: lean harder on calibration, enforce responsible reviewing, and pilot new formats where they add value. Authors can adapt by writing for calibration clarity, investing in artifacts and stewardship, and engaging with professionalism, especially when outcomes disappoint. The science, and the community, depend on it.