🔊 Release Note (2025-11-20): Gemini-3.0-Pro, GPT-5.1 and Benchmark page
-
Dear CSPaper Review Users,
We’re excited to announce two major enhancements to CSPaper Review!

Support for Gemini-3.0-Pro and GPT-5.1
You can now select the latest models — Gemini-3.0-Pro and GPT-5.1 — as the primary engines powering your agent workflows. As always, we also provide full benchmarking results for these new models.
These models are available as a free trial for now. They will eventually become part of our premium offering once we finalize their long-term integration.
A fun anecdote: many users previously told us that GPT-5 tended to be "meaner" than Gemini-2.5-Pro. We’re curious — does this still hold for GPT-5.1 and Gemini-3.0-Pro? Let us know!
New Benchmark Dashboard
We’ve launched a dedicated benchmark page:
https://cspaper.org/benchmarkThis page provides an up-to-date, comprehensive overview of performance across LLMs and venues (conference + track).
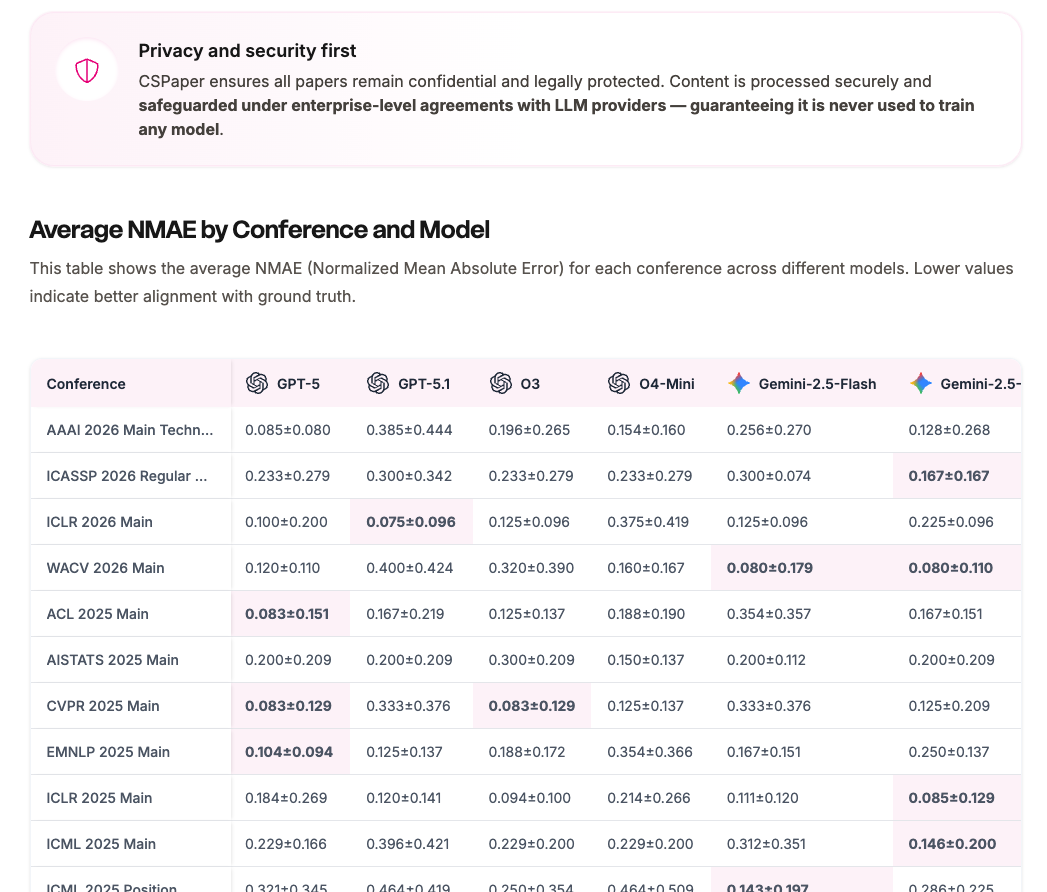
You’ll also find detailed explanations of our metrics and what they mean in practice. From the latest results, we observe that:
- LLM agents behave differently depending on the venue-specific review workflows.
- Top performers include GPT-5, Gemini-2.5-Pro, Gemini-3.0-Pro, and GPT-5.1.
We will continue improving the robustness and reliability of our benchmarks by expanding datasets and refining evaluation metrics.
We Welcome Your Feedback!
We’re already planning the next wave of features — but your voice guides our direction.
Please share your suggestions, feature requests, or bug reports. You can reply below or reach us anytime at support@cspaper.org.Cheers,
The CSPaper Team ️
️