🔊 Release Note (2025-11-06): LLM selection, benchmarking as a guide, and GenAI text analysis
-
Dear CSPaper Review Users,
After extensive preparation and foundational work, we’re thrilled to announce the release of CSPaper Review v1.2.0!

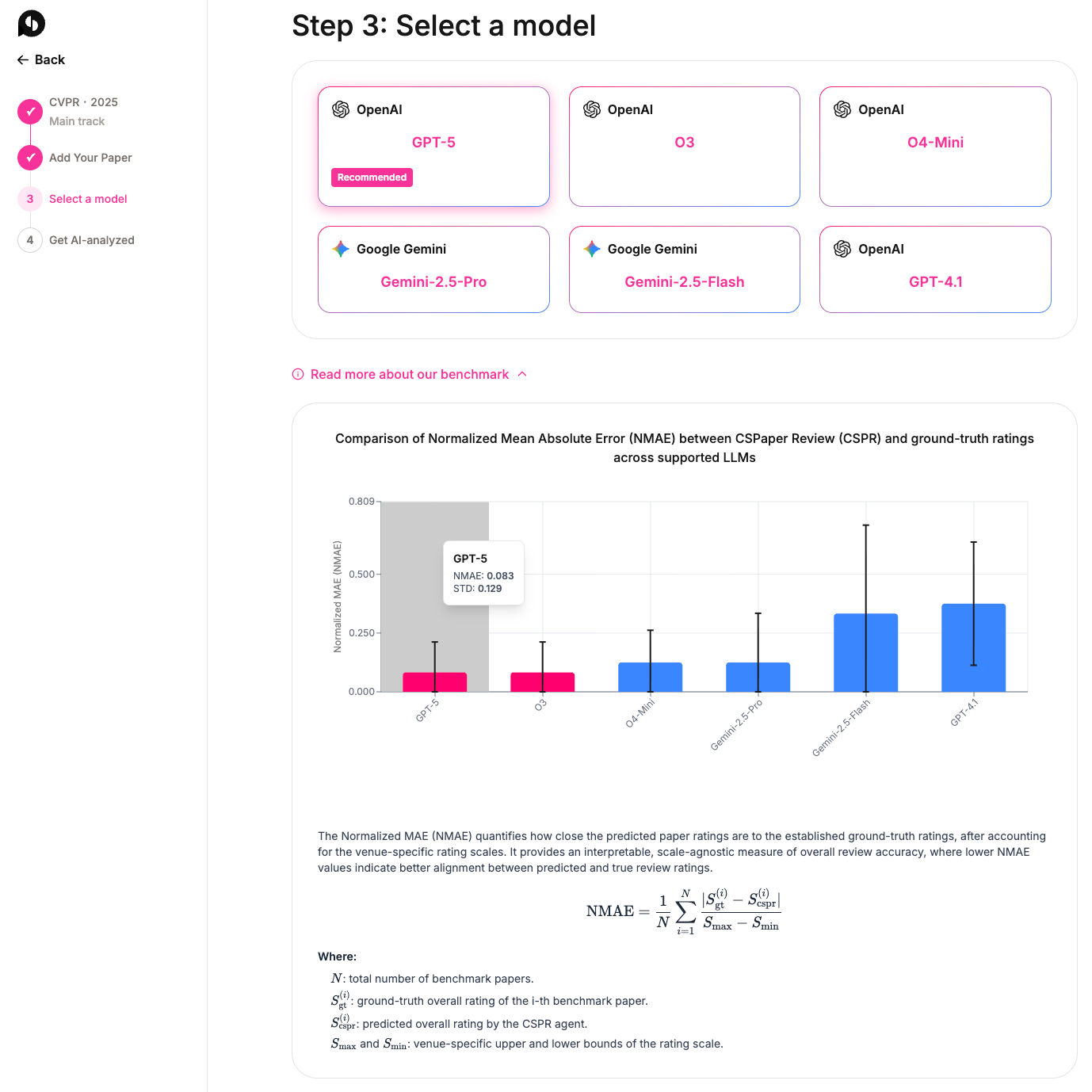
 Choose Your Favorite LLM
Choose Your Favorite LLMWe’ve introduced a new step after paper upload that allows you to select your preferred LLM for generating reviews.
Currently supported models include:GPT-5, O3, O4-mini, GPT-4.1, Gemini-2.5-pro, and Gemini-2.5-flash.
We plan to expand this list based on community feedback and our benchmarking capabilities across supported venues (conference + track).
 Guided by Benchmarking Results
Guided by Benchmarking ResultsWhen selecting a model, CSPaper now displays recommended LLMs together with benchmarking results for the selected conference and track.
We visualize comparative performance (measured by NMAE) along with standard deviation (STD) values to make an informed model choice.Normalized Mean Absolute Error (NMAE) measures how closely the predicted paper ratings align with ground-truth ratings, normalized to account for each venue’s rating scale. Lower NMAE values indicate better accuracy.

 Note: Benchmark results are venue-specific and continuously updated as:
Note: Benchmark results are venue-specific and continuously updated as:- Our benchmark dataset (currently 150 annotated papers) expands.
- The review agent’s prompts and templates are refined, affecting LLM performance dynamics.
- LLMs might update their sub-versions.
 GenAI Text Analysis (Pilot)
GenAI Text Analysis (Pilot)As part of our roadmap, we’re piloting a new feature — GenAI Content Analysis — for selected venues:
TheWebConf 2025, KDD 2025, and CVPR 2025.
Each review may now include a section titled “GenAI Content Analysis”, offering a qualitative assessment of AI-assisted writing likelihood:
- None / Minimal
- Partial / Moderate
- Extensive / Intensive
If “Partial / Moderate” or “Extensive / Intensive” is detected, the agent will provide concise justifications with direct evidence, referencing specific sections, pages, paragraphs, or sentences.

 A Glimpse Into the Future
A Glimpse Into the FutureWe have fully refactored our agent architecture to enable the next generation of review intelligence:
- High-fidelity score calibration — ensuring review text and scores are more coherently aligned.
- Cross-review ranking — compare how your reviews rank among all generated reviews for the same venue.
- Custom review agents — create your own venue-specific agents with tailored review logic.
Thank you for supporting CSPaper.org and contributing to our journey of building transparent, reliable, and intelligent academic review systems.
— The CSPaper.org Team