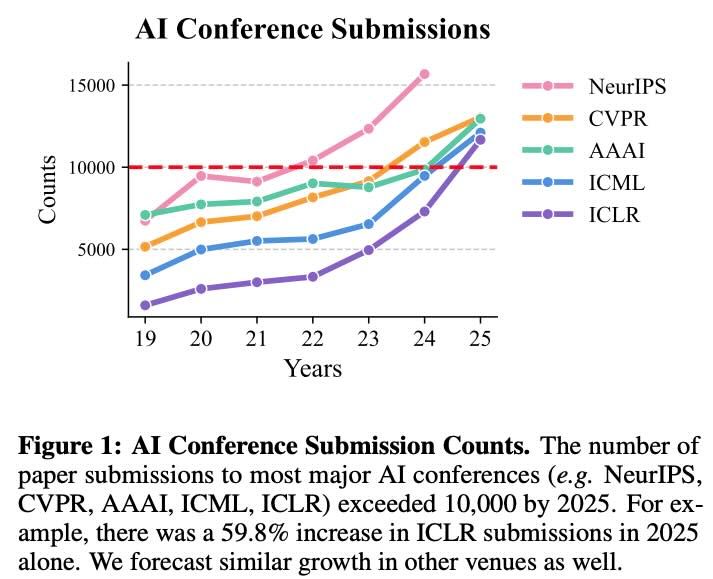
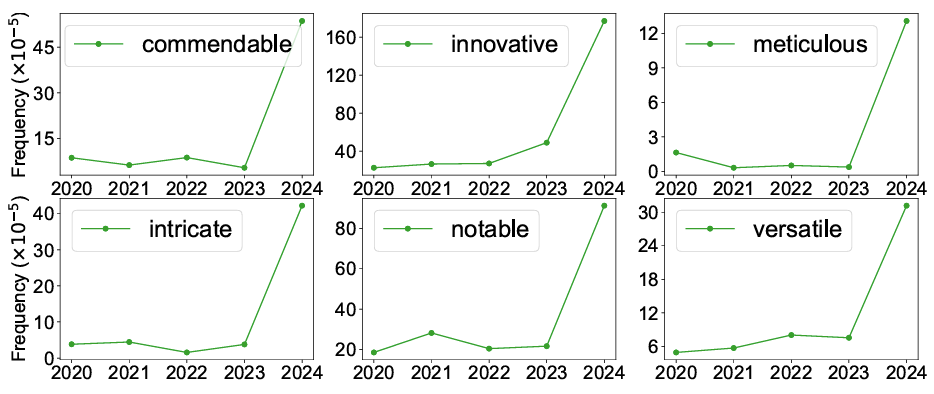
The final decisions for EMNLP 2025 have been released, sparking a wave of reactions across research communities on social media such as Zhihu and Reddit. Beyond the excitement of acceptances and the disappointment of rejections, this cycle is marked by a remarkable policy twist: 82 papers were desk-rejected because at least one author had been identified as an irresponsible reviewer. This article provides an in-depth look at the decision process, the broader community responses, and a comprehensive table of decision outcomes shared publicly by researchers.
[image: 1755763433631-screenshot-2025-08-21-at-10.02.47.jpg]
Key Announcements from the Decision Letter
The program chairs’ decision email highlighted several important points:
Acceptance Statistics
8174 submissions received.
22.16% accepted to the Main Conference.
17.35% accepted as Findings.
82 papers desk-rejected due to irresponsible reviewer identification.
Desk Rejections Linked to Reviewer Misconduct
A novel and controversial policy: authors who were flagged as irresponsible reviewers had their own papers automatically desk-rejected.
The official blog post elaborates on what qualifies as irresponsible reviewing (e.g., extremely short, low-quality, or AI-generated reviews).
Camera-Ready Submissions
Deadline: September 19, 2025.
Authors must fill in the Responsible NLP checklist, which will be published in the ACL Anthology alongside the paper.
Allowed: one extra page for content, one page for limitations (mandatory), optional ethics, unlimited references.
Presentation and Logistics
Papers must be presented either in person or virtually to be included in proceedings.
Oral vs. poster presentation decisions will be finalized after camera-ready submission.
Registration deadline: October 3 (at least one author), with early in-person registration by October 6 due to Chinese government approval processes (conference will be in Suzhou).
The Desk Rejection Controversy: 82 Papers Removed
This year’s 82 desk rejections triggered heated debates. While ensuring reviewer accountability is laudable, punishing co-authors for the actions of a single irresponsible reviewer is unprecedented and raises questions about fairness:
Collective punishment? Innocent co-authors had their work invalidated.
Transparency gap: The official blog post provided criteria, but the actual identification process is opaque.
Potential chilling effect: Researchers may hesitate to serve as reviewers for fear of inadvertently harming their own submissions.
The policy signals a stronger stance by ACL conferences toward review quality enforcement, but it also underscores the urgent need for more transparent, community-driven reviewer accountability mechanisms.
Community Voices: Decisions Shared by Researchers
To capture the breadth of community sentiment, below is a comprehensive table compiling decision outcomes (OA = overall average reviewer scores, Meta = meta-review score) shared publicly across Zhihu, Reddit and X.
This table is exhaustive with respect to all shared samples from the provided community discussions.
OA Scores (per reviewer)
Meta
Outcome
Track / Notes / User
4, 4, 3
4
Main
Meta reviewer wrote a detailed essay, helped acceptance
3.5, 3.5, 2
—
Main
Initially worried, accepted to main
2.67 (avg)
3.5
Main
Shared proudly (“unexpected”)
3.67
4
Main
Confirmed traveling to Suzhou
3.33 (4, 3.5, 2.5)
3
Rejected
Author frustrated, “don’t understand decision”
3.0
3
Rejected
Hoped for Findings, didn’t get in
3.0
3.5
Main (short)
Track: multilinguality & language diversity; first-author undergrad
2.33
3.5
Findings
Efficient NLP track
3.33
3.5
Main
Efficient NLP track
3.5, 3.5, 2.5
2.5
Findings
Meta review accused of copy-paste from weakest reviewer
3, 3.5, 4
3
Main
Theme track
4, 3, 2
2.5
Rejected
One review flagged as AI-generated; rebuttal ignored
4.5, 2.5, 2
—
Rejected
Meta only two sentences
3.38
3.5
Main
Rejected at ACL before; accepted at EMNLP
2, 3, 3
3
Rejected
RepresentativeBed838
3.5, 3, 2.5
3.5
Rejected
Author shocked
3, 3, 3
3
Rejected
Multiple confirmations
5, 4, 3.5
4.5
Main
Track: Dialogue and Interactive Systems
3.5, 4.5, 4
4
Main
GlitteringEnd5311
3, 3.5, 3.5
3.5
Main
Retrieval-Augmented LM track
2.5, 3, 3
3
Findings
After rebuttal challenge; author reported meta reviewer
1.5, 3, 3 → rebuttal → 2.5, 3, 3.5
3.5
Main
Initially borderline, improved after rebuttal
3.67
3
Main
Computational Social Science / NLP for Social Good track
4, 3, 3
3
Main
Low-resource track
3.5, 3.5, 3
3.5
Main
Low-resource track
4, 3
3
Findings
Author sad (“wish it was main”)
Overall 3.17
3
Findings
JasraTheBland confirmation
Overall 3.17
3.5
Main
AI Agents track
Overall 3.17
3
Findings
AI Agents track
4, 3, 2
3.5
Main
Responsible-Pie-5882
3.5 (avg)
3.5
Main
Few_Refrigerator8308
3, 3, 3.5 → rebuttal → 3.5,3.5,3.5
4.0
Main
LLM Efficiency track
3.5, 2.5, 2.5
3
Findings
FoxSuspicious7521
3, 3.5, 3.5
3.5
Main
ConcernConscious4131 (paper 1)
2, 3, 3.5
3
Rejected
ConcernConscious4131 (paper 2)
3, 3, 3
3
Rejected
Ok-Dot125 confirmation
3.17 (approx)
3.5
Main
Old_Toe_6707 in AI Agents
3.17 (approx)
3
Findings
Slight_Armadillo_552 in AI Agents
3, 3, 3
3
Rejected
Confirmed again by AdministrativeRub484
4, 3, 2
3.5
Main
Responsible-Pie-5882 (duplicate entry but reconfirmed)
3.5, 3.5, 3
3.5
Main
breadwineandtits
3, 3, 3
3
Accepted (Findings or Main unclear)
NeuralNet7 (saw camera-ready enabled)
2.5 (meta only)
2.5
Findings
Mentioned as borderline acceptance
3.0
3.0
Findings
shahroz01, expected
4, 3, 2
3.5
Main
Responsible-Pie-5882 (explicit post)
3.5, 3.5, 2.5
2.5
Findings
Practical_Pomelo_636
3, 3, 3
3
Reject
Multiple confirmations across threads
4, 3, 3
3
Findings
LastRepair2290 (sad it wasn’t main)
3.5, 3, 2.5
3.5
Rejected
Aromatic-Clue-2720
3, 3, 3.5
3.5
Main
ConcernConscious4131
2, 3, 3
3
Reject
ConcernConscious4131
3, 3, 3
3
Reject
Ok-Dot125 again
3.5, 3.5, 3
3.5
Main
Few_Refrigerator8308 second report
3.5, 3, 2.5
3.5
Rejected
Aromatic-Clue-2720
4, 3, 2
3.5
Main
Responsible-Pie-5882 final confirmation
3.5, 3.5, 3
3.5
Main
Reconfirmed across threads
3, 3, 3
3
Rejected
Reported multiple times
2.5 (OA overall)
3.0
Findings
Outrageous-Lake-5569 reference
Patterns Emerging
From the collected outcomes, some patterns can be observed:
Meta ≥ 3.5 often leads to Main acceptance (even when individual OA scores are mediocre, e.g., 2.67).
Meta = 3 cases are unstable: some lead to Findings, others to Rejection, and in a few cases even Main.
Meta < 3 almost always means rejection, with rare exceptions.
Reviewer quality matters: multiple complaints mention meta-reviews simply copy-pasting from the weakest reviewer, undermining rebuttals.
This highlights the high variance in borderline cases and explains why so many authors felt frustrated or confused.
Conclusion: Lessons from EMNLP 2025
EMNLP 2025 brought both joy and heartbreak. With a Main acceptance rate of just over 22%, competition was fierce. The desk rejections tied to reviewer misconduct added an entirely new layer of controversy that will likely remain debated long after the conference.
For researchers, the key takeaways are:
Meta review scores dominate: cultivate strong rebuttals and area chair engagement.
Borderline cases are unpredictable: even a 3.5 meta may result in Findings instead of Main.
Reviewer accountability is a double-edged sword: while improving review quality is necessary, policies that punish co-authors risk alienating the community.
As the field grows, the CL community must balance fairness, rigor, and transparency—a challenge as difficult as the NLP problems we study.
 1
1
 1
1
 3
3
 3
3
 6
6